- A+
2. 大饼道具的属性包括生命值、魔法值、攻击力、防御力、命中率等等。
游戏介绍
《新开传奇私服-复古怀旧私服》是完美世界倾力打造的一款大型多人在线角色扮演类手机网络游戏,、采用Unity3D引擎技术,完美还原了PC端游的画质效果和操作体验。同时适配移动设备安全系统以及触摸屏操作方式,全面升级攻击和技能效果,带来更爽快战斗!
sf传奇
为了更好地管理传奇私服发布网,图表建立是至关重要的。这些图表可以提供关于玩家人数、经济状况、游戏进展等方面的关键数据。准确的图表可以帮助游戏开发商更好地了解玩家需求,以便做出相应的调整和改进。
传奇私服与勇士刷图职业排行
单笔128元,赠送20000钻石+50w银票+100万绑定宝石*100
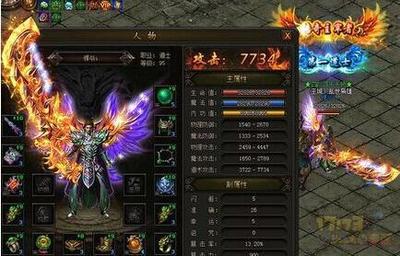
sf传奇网站
1. 线下活动的组织:传奇私服发布网怀旧复古传奇私服发布网的玩家通常会组织线下活动,比如聚会、比赛等,增进玩家之间的交流与沟通。
然后等待5分钟便可以获得腾讯游戏专属的QQ账号、Q币和微信号哦!
3. 官方推荐:有些传奇私服发布网可能得到官方的认可和推荐。在官方网站或社交媒体上,可以找到一些官方推荐的传奇私服发布网信息。这些服务器通常会提供更好的游戏环境和更完善的客户端支持。
2.1 独特的剧情和任务设计
新开传奇私服复古60版本私服bug(新开传奇私服复古60版本新开传奇私服)
3. 游戏运行卡顿的解决方法
怀旧服86版本传奇私服发布网将持续更新和改进游戏内容,以满足玩家的需求。未来可能会添加更多的职业、副本和活动,给玩家带来更多的游戏乐趣。
【福利内容】累计登录可得60钻石和100w金币7天登陆送橙装、海量经验以及稀有材料道具等奖励
传奇私服发布网70版本是传奇私服发布网官方推出的一次特殊版本,旨在回馈广大玩家。相比普通版本,传奇私服发布网版本提供了更多的游戏资源和福利,让玩家能够更快地体验游戏的乐趣。70版本也引入了全新的副本和装备,为玩家带来了全新的挑战和收获。

您可以选择一种方式支持本站
赏